My Thoughts Heading Into Toronto: Search, AI Output, & Paths to Consensus
The current condition-based Search definition was said to offer clarity, but I believe it instead brings ambiguity and the potential for abuse. It carves out exceptions for context-window processing that are so broad as to potentially sweep into “Search” virtually every AI chatbot on the market as well as most of what constitutes Retrieval Augmented Generation (RAG).
This ambiguity arises in part because of the removal of the “AI Output” category between the v4 and v5 drafts. In its absence, we’re left to guess and bicker over where search output ends and AI output begins.
The current Search definition further risks becoming a tool AI companies can use for “manufacturing consent” for certain AI search products. And the lack of an AI Output category restricts publishers from expressing the most important preferences that matter to them.
My current thinking is that any condition-based vocabulary is likely to be a dead end path to consensus, though my mind remains open to solutions I can’t currently see.
At the end of this letter, I’ll try to offer some thoughts on alternative productive paths forward towards consensus. The short of it is that I think we need significant architectural changes, or we’re going to keep spinning our wheels.
The current Search definition is endlessly ambiguous
Proponents of the current Search definition claim it offers clarity because (purportedly) only two bright-line conditions need to be met: 1) a reference to the location of the asset and, 2) verbatim representation of the asset.
According to the current v5 draft, “a preference to allow Search usage enables the presentation of links and titles in what is considered ‘traditional’ search results.”
(As an aside, it might not even achieve that for long because Google is now using AI to re-write publisher titles in search results!)
But the Search definition — along with the “Search Application” definition it incorporates — is actually a LOT more complicated than the “two conditions” framing might reasonably lead one to believe.
I’ll tackle the most consequential ambiguities below, but there are others I’ll skim over, including:
- Can an AI system be a user of a “Search Application” (such as during fan-out, or in the context of “AI agents”)?
- What does it mean to “locate” an asset?
- Does “enables users [to] locate items” mean that needs to be the application’s primary purpose, or just something it could be used to do?
- What is a “data store”? And doesn’t that make basically everything a “Search Application”?
- What does it mean to be “using” assets? We know it means at least “ranking,” “presentation,” and “output,” but it’s open-ended and could mean a lot more.
- What does “presentation of any asset” mean? Do AI summaries count?
- What does “ranking” mean? Does it include probabilistic ranking of potential AI output tokens, or only ranking of assets?
And then there is perhaps the most difficult and important question …
Where does “search output” end and “AI output” begin? We cannot avoid confronting this question!
As I understand it, version 4’s “AI Output” category was removed in the latest draft under the argument that it would be easier to focus our efforts on first achieving consensus on a narrower vocabulary.
I think that, by removing that category, we have actually introduced incredible ambiguity into the draft. You cannot draw the shape of an object without also drawing the relief of it.
By removing “AI Output” from the latest draft, we’re left with even more ambiguity about the line between AI-generated output and “search output.”
The two conditional limits of the Search definition only apply to the “presentation of any asset that is included in search output”.
But that begs the question: what exactly counts as “search output”?
The draft does not define the term.
One might reasonably be inclined to say “search output” means any output from a “Search Application.”
But, if so, that’s quite broad because a “Search Application” is defined loosely as any “system that enables users [to] locate items on the internet or in a specific data store.”
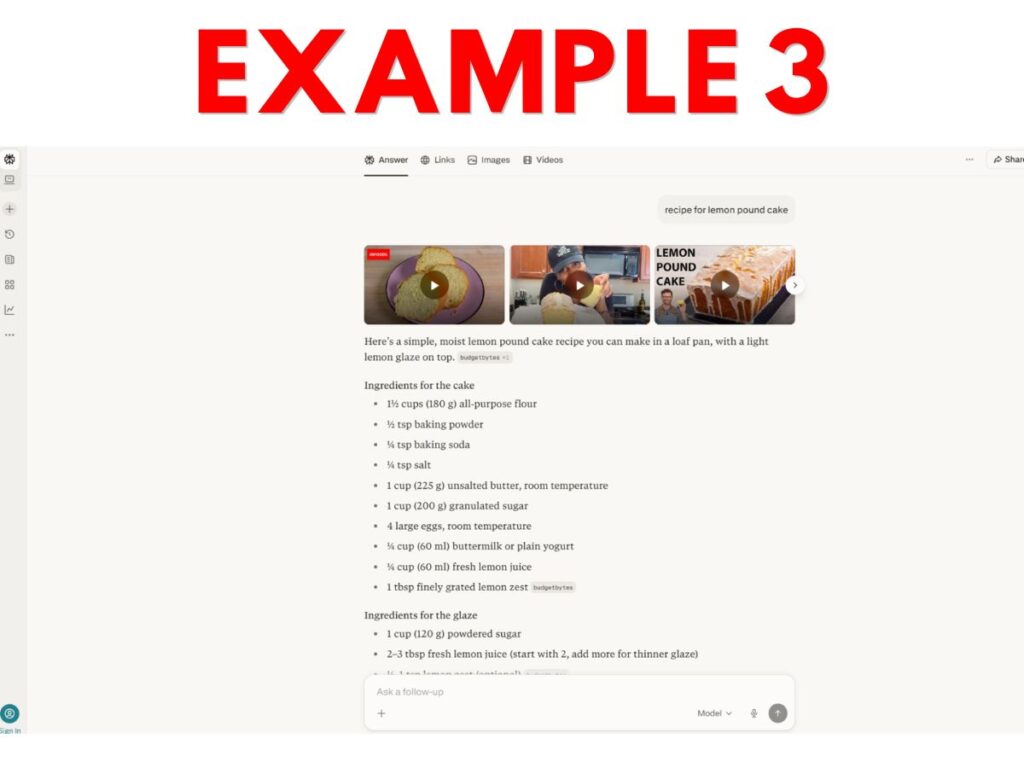
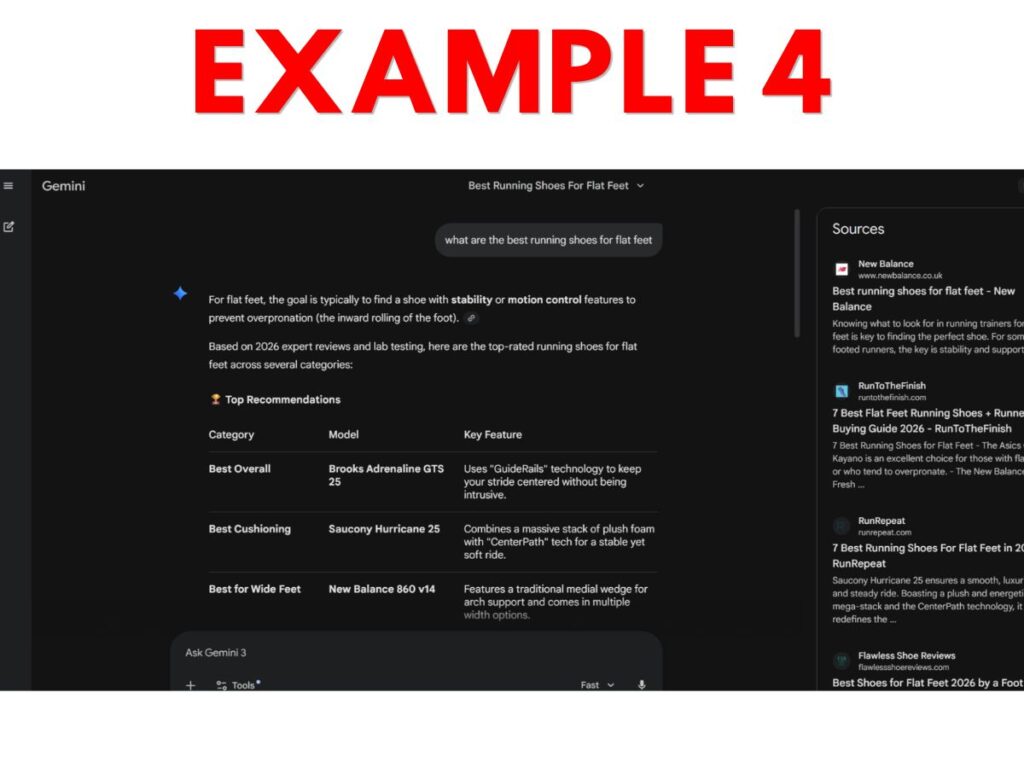
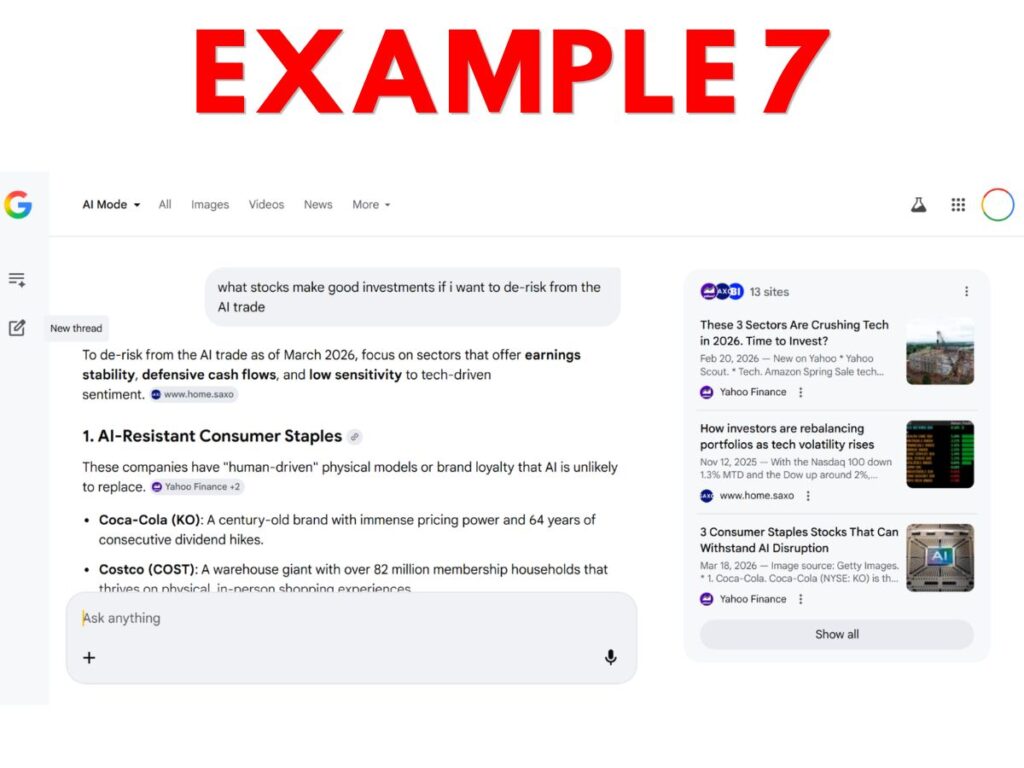
Consider the following examples from prominent AI applications. Can you easily tell which of these, or which parts, count as “search output”?
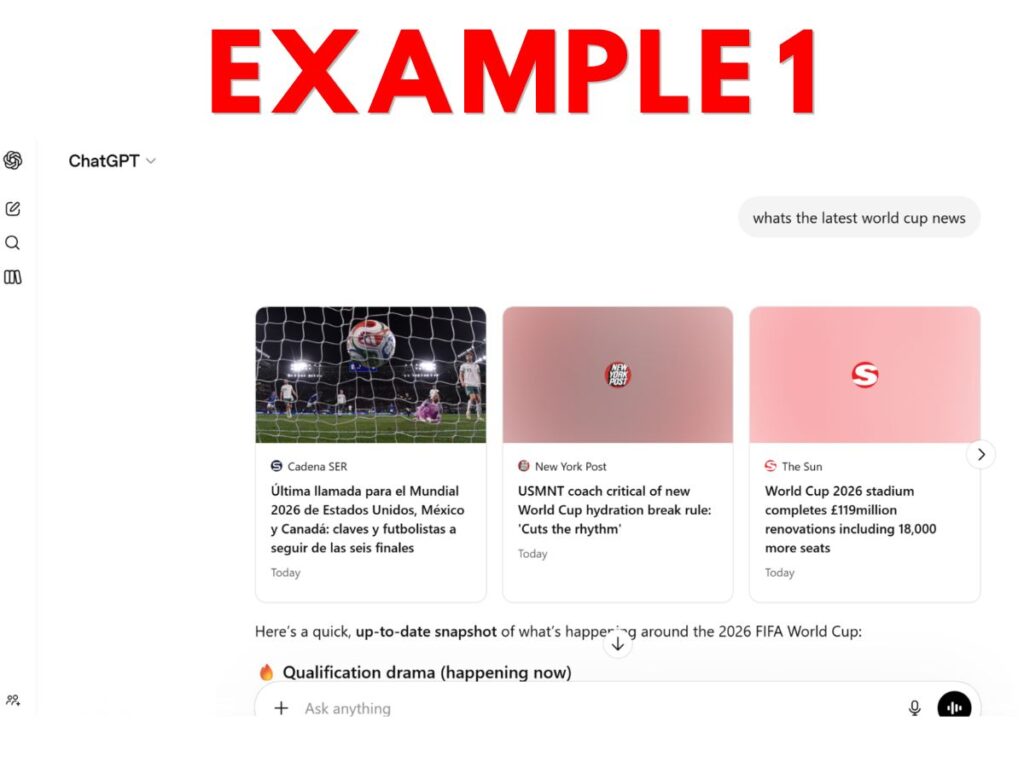




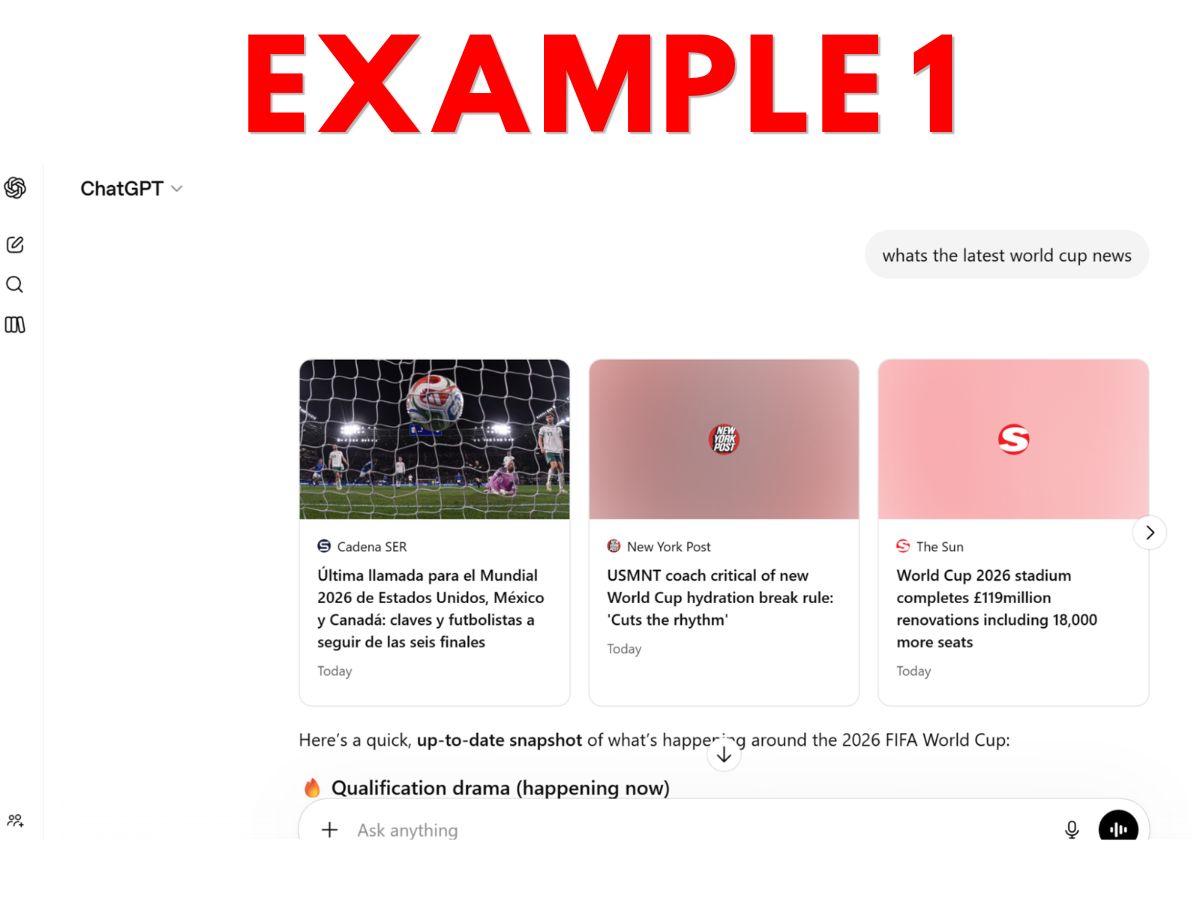




- Example 1 – ChatGPT World Cup output that includes prominent links to news websites, followed by AI-generated content.
- Example 2 – ChatGPT AI itinerary for Peru that includes AI content, links in a side panel, and embedded images drawn from websites (with links only visible upon clicking the image).
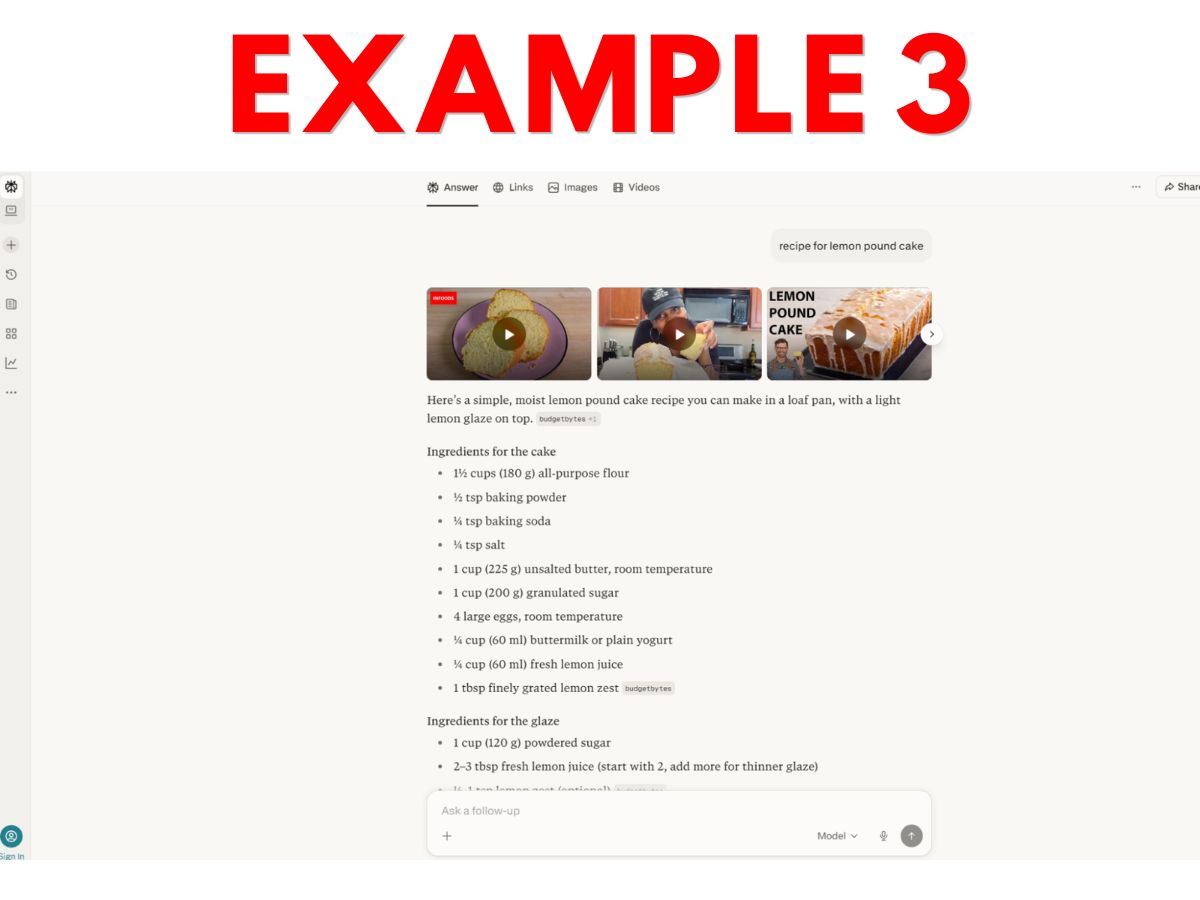
- Example 3 – Perplexity lemon pound cake AI recipe cobbled together from multiple sources, with tiny greyed-out clickable links given to some sources.
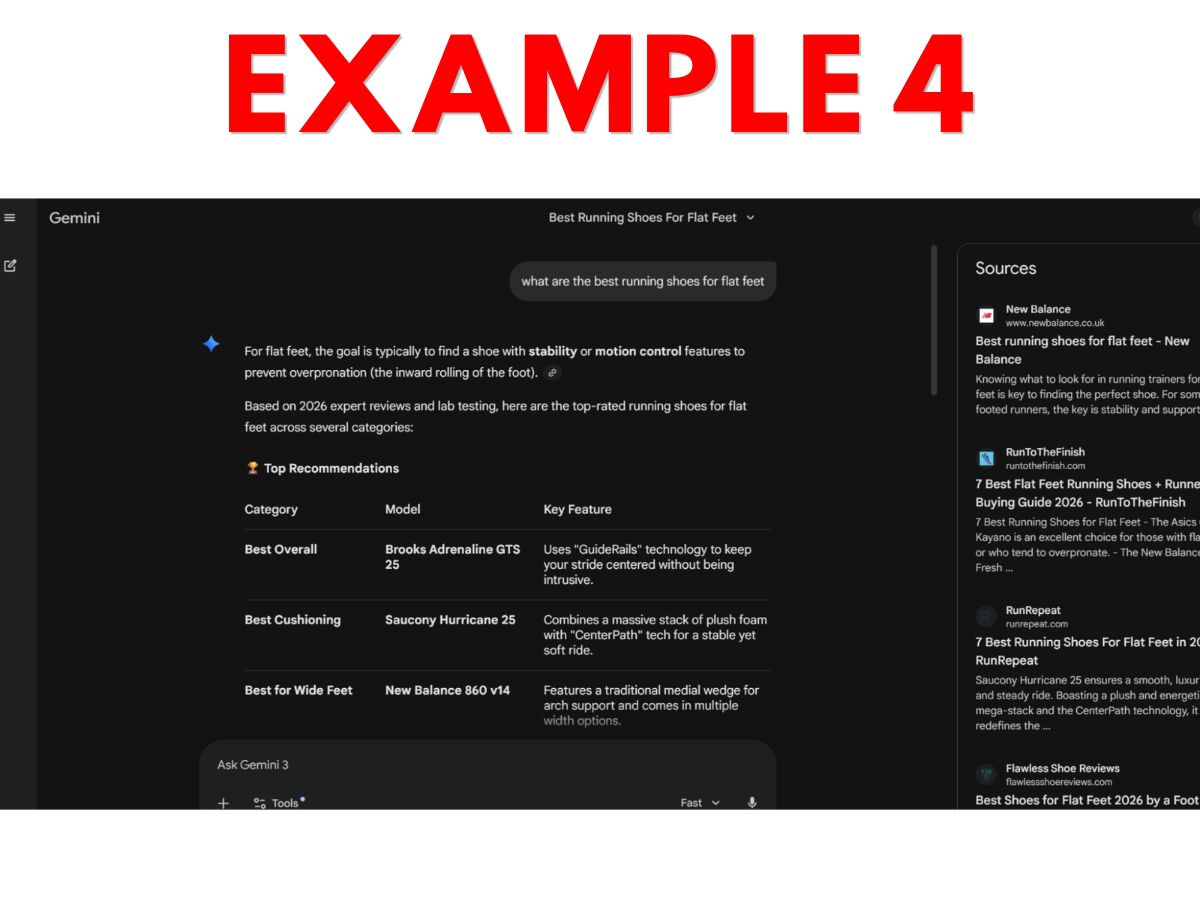
- Example 4 – Gemini running shoe AI-generated comparison, with sources that appear in a side panel but only after the user clicks a small “sources” button located at the bottom of the response.
- Example 5 – Claude AI child safety question response that includes no references to sources.
- Example 6 – Claude AI child safety question response that includes small modal/hover links to web sources (after user asked for sources).
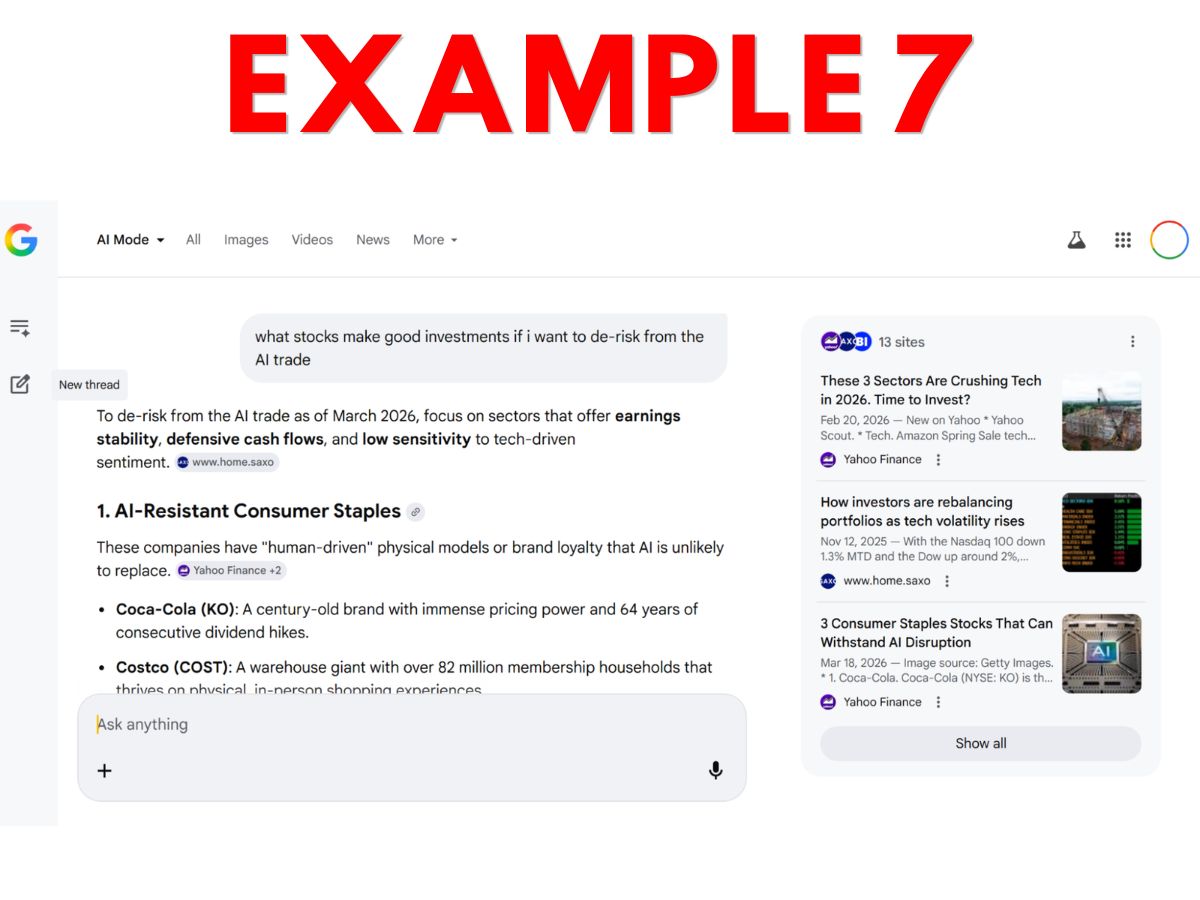
- Example 7 – Google AI Mode financial advice output that includes generated output and links to websites in side panels and in clickable buttons.
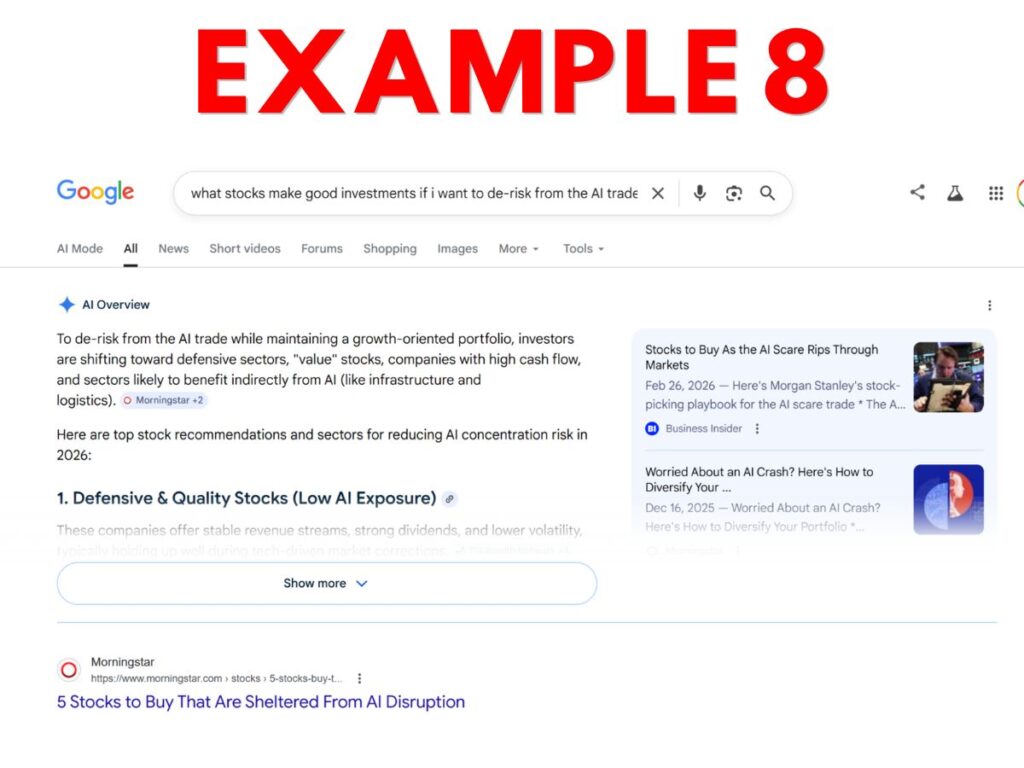
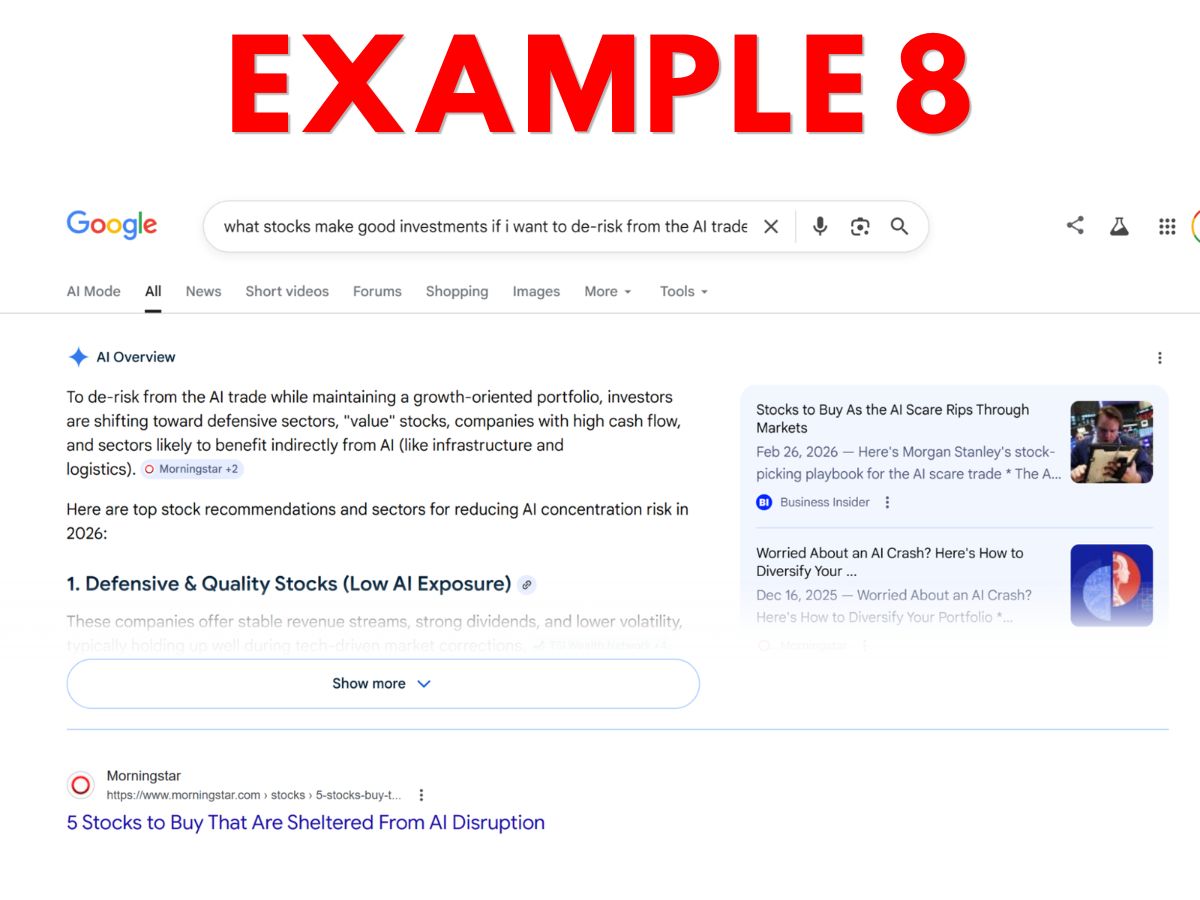
- Example 8 – Google AI Overview financial advice output that includes generated output, side panel links, and clickable button links.
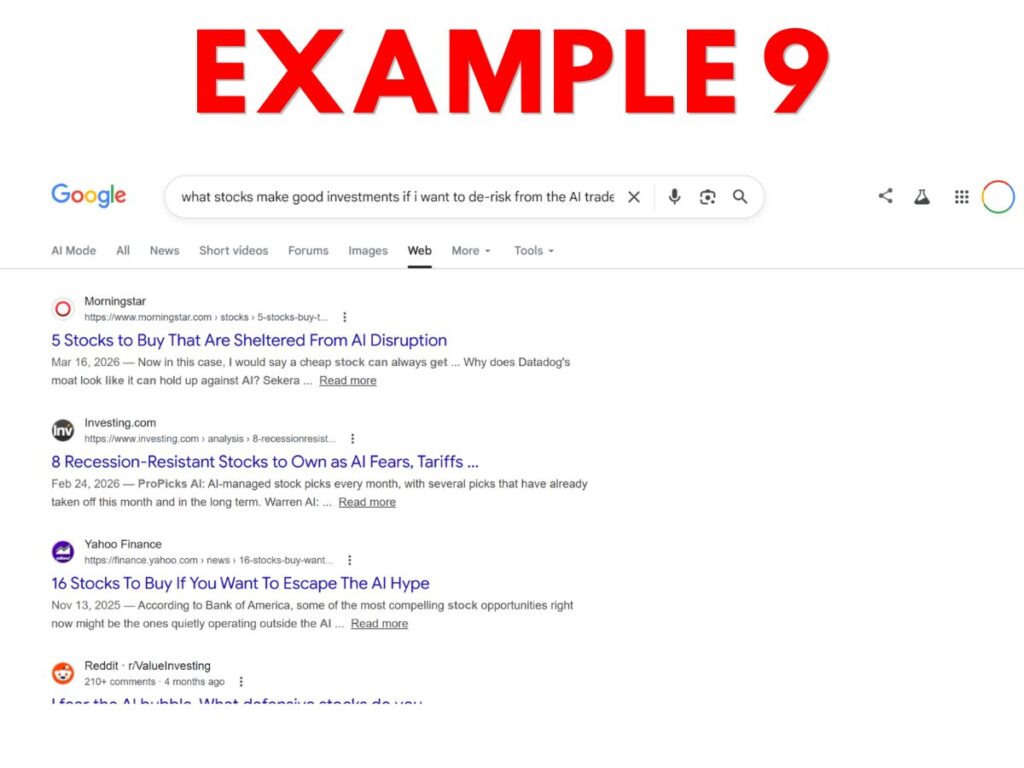
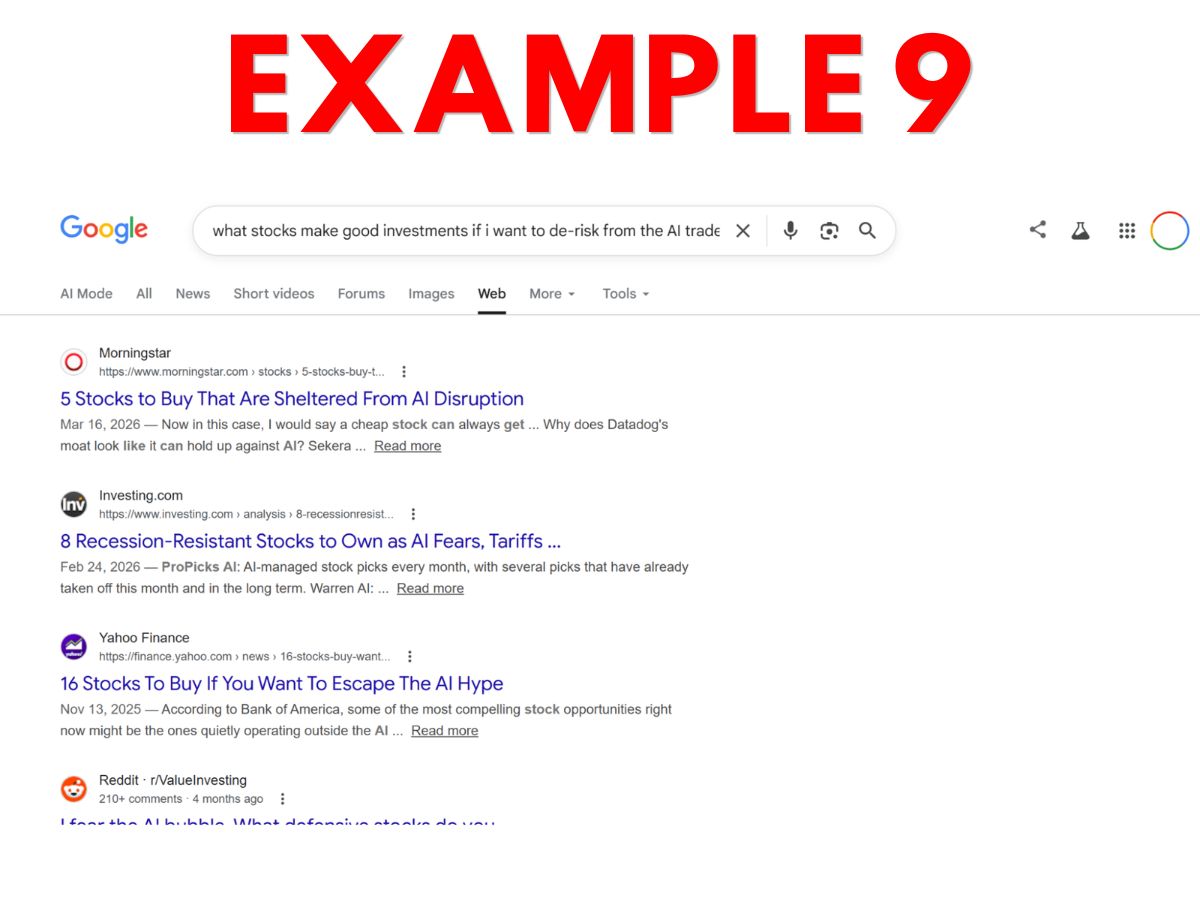
- Example 9 – Google “Web” results for the same financial advice query, including only links to, and verbatim excerpts from, websites.
- Example 10 – What’s App Meta AI Toronto activity chat response, with small unlabeled link icons that lead to websites when clicked.
Personally, I think many website owners will make their elections expecting that only Example 9 would be considered “search output.” This expectation seems reasonable since the last sentence of the Search definition talks about enabling “traditional” search results – and 9 is the only example that feels traditional.
But, from a textual reading of the current definition, arguably most or even all 10 constitute “search output” because all reflect output from applications that “enable users [to] locate items on the internet or in a specific data store.”
Such a broad result would be bad for the web ecosystem though, because most of these applications offer substitutive output and in practice do not actually send enough referral traffic to support the creation of the content they feed off. Pew Research found that “[f]or searches that resulted in an AI-generated summary, users very rarely clicked on the sources cited.” The primary purpose of many of these applications is clearly something other than connecting users to assets. Just look at how hard they make it to even spot some of those little teeny tiny source links (or how they hide them away within modals)!
There’s also a third interpretation, which is to split the baby and say the AI-generated content portion of each example is not search output, but that the actual links and titles are. I’ll address this Solomonic approach in detail in the next section. If I were a lawyer for an AI search company with market dominance, this is the interpretation I’d try to defend in courts and to regulators. For everyone else, though, this interpretation would lead to perverse and unfair outcomes for asset owners. More on that in a second.
The bottom line is that, without an “AI Output” definition to bound “search output,” I think it’s basically impossible to objectively assess where “search” ends and “AI” begins based solely on output (especially with a massive carve-out for “internal processing”).
We really ought to either define both Search Output and AI Output, or else define neither and find an alternate approach.
As it stands, we are left with a vocabulary that is ambiguous and thus wide open to exploitation by the owners of automated processing systems ….
The current Search definition could be used to manufacture consent for substitutive AI content generation
So, about that Solomonic third option. You might try to split the baby and argue that “search output” only includes anything with a link and a verbatim title (i.e., the blue boxes) and that any AI-generated content (red box) is just … something undefined.
That’s a plausible (if a bit circular) textual interpretation, but it could be wielded by entities with massive leverage to achieve incredibly unfair and unjust consequences.
Importantly, we can logically infer that “search output” is only a subset use of the many broader use cases which a “search = y” preference would enable. For example, the definition explicitly draws distinctions between “output” and other permitted uses like “ranking” or “internal processing.”
What this means is that the Search definition would broadly enable a LOT of AI processing on assets — potentially including everything that is required to implement a RAG application and even to generate AI summaries of those assets.
And, perversely, since those AI summaries are not “search output,” the requirement for a link to the source doesn’t even apply!
This seems profoundly unfair. The blue box assets clearly ARE being processed by AI. They are being presented within the red box output to some degree, just not always verbatim. The red box output wouldn’t even be possible without the blue box assets. But, if you take this third Solomonic approach to parsing our examples, this is the logical outcome you’ll arrive at — you’ve split the baby and thus, in my opinion, killed it.
And that would leave us right back at the same Hobson’s Choice dynamic as the status quo for publishers, where the only way to opt out of contributing to AI summaries is to also opt out of being found via search. Except, now, potentially there is a veneer of consent to this situation if publishers have affirmatively expressed “search = y” and thus “consented” in a sense to all that RAG (err, I mean, “internal”) processing.
But wait … this raises a second and even thornier problem – because this example application is not just processing the blue box (i.e., linked) assets: it’s also processing (many more) assets that do not appear with a link or title at all!
A “search = yes” preference would enable a Search Application to:
1) use an asset within an internal RAG context window,
2) generate substitutive AI outputs, drawing from that and other assets, and;
3) present no reference at all to the asset anywhere on the page.
Incredibly, the owner of the assets thus might never even be able to know if their assets were processed this way.
This outcome may seem absurd (it is), but I think the current draft quite specifically allows for this scenario.
It permits “[i]nternal processing of assets” by AI models “to perform ranking and presentation” and further states that “[a]n asset can be used in ranking, but not present in output.”
So we’re left with a situation where a website owner expressing a “Search = yes” preference has perhaps unwittingly consented to any product plausibly labeled “AI search” being able to vacuum up their assets, launder them through an AI context window with other assets, and generate substitutive outputs that can compete with the asset owner – all while providing no link at all to the asset owner.
Proponents of the draft might argue that this is no different than “traditional” 10-blue-link search, where hundreds of websites are processed but only ~10 are presented to the user.
But it is in fact enormously different for at least two reasons.
First, major search engines already allow website owners to opt out of traditional search results via robots.txt directives. No such consent mechanisms currently exist for many of the largest AI search products, including AI Overviews and AI Mode. And, without an “AI Output” category, this working group’s draft wouldn’t offer publishers a consent mechanism either.
Indeed, the lack of publisher consent for AI Overviews and AI Mode is a hotly disputed legal topic. In the UK, the Competition and Markets Authority launched an investigation in January. In the EU, the European Publishers Council filed an antitrust complaint. And, in the USA, prominent publisher Penske Media has an ongoing suit involving these issues.
My worry is that the current Search definition could be used to manufacture consent that does not really exist.
Many or most website owners are likely to select “Search = y”. And then Google – which has consistently taken the position that AI Mode and AI Overviews are a core part of “Search” – would be able to go to regulators and courts and say “hey, look at all these ‘search = y’ preferences. See, AI Mode and AI Overviews are consensual after all!”
There is also a second difference: in traditional search, websites ranked #11-100+ are not shown on the front page, and thus not directly contributing to the search output shown to the user.
LLMs work quite differently. Anything and everything included in the context window of an LLM contributes to and affects the output. Studies have found that “even the smallest of perturbations, such as adding a space at the end of a prompt, can cause the LLM to change its answer.”
Once an asset is included in a context window during internal processing, a search application can’t really filter that asset “out” of the output. The entire output is a weighted statistical amalgamation of everything that was included in the foundation model and everything included in the context window.
So, unlike traditional search results, the value of “AI search” output derives in part from all assets included in the context window.
This is not even a particularly controversial statement. Take a look at the marketing for any major AI search product. The whole value proposition of these products is that they are able to digest and synthesize more assets that a human can.
For example, just look at what Google said when announcing AI Mode (emphasis supplied):
“What makes this experience unique is that it brings together advanced model capabilities with Google’s best-in-class information systems, and it’s built right into Search. You can not only access high-quality web content, but also tap into fresh, real-time sources like the Knowledge Graph, info about the real world, and shopping data for billions of products. It uses a “query fan-out” technique, issuing multiple related searches concurrently across subtopics and multiple data sources and then brings those results together to provide an easy-to-understand response. This approach helps you access more breadth and depth of information than a traditional search on Google.”
So, whereas in traditional search websites ranked #11-100 do not contribute to the output, in AI search the inclusion of content from that long-tail of websites is actually the explicit value proposition of the AI search products!
The bottom line is that shipping the current Search definition could cause a lot of harm to the open web, and in my opinion would primarily work to consolidate the web further under a single search company that has been called a “recidivist monopolist” by the United States Department of Justice.
So where do we go from here?
This section is a little more mushy because the path forward is mushy.
What I can say with the most conviction is that I believe we either need an AI Output category in the draft, or we need to jettison the Search category too.
We will never achieve consensus with one definition but not the other. I have talked to enough group members at this point to be certain of that.
And, even if we somehow do, it will end in confusion and disaster for the web.
Second, I am skeptical that we will be able to find some magical combination of output-based conditions that will solve this ambiguity without creating more. Output or display conditions are simply too far abstracted from what actually matters, and we’re working in an environment that is far too fluid for such abstractions to have durability.
Instead, I think we should go back to first principles and consider what actually matters to asset owners – and then work on crafting a structure that’s oriented around the preferences of those humans, not what would be economically convenient to large AI companies.
We have to ask ourselves, do we want a controlled web environment or an expressive web environment?
The appeal of a controlled web environment is that it’s simple and binary. Great for bots and AI agents (also great for monopolists, by the way).
But the web is only interesting because of humans – and humans will always be expressive, complex, and diverse.
I believe we should re-center our work around finding a structure that supports the diversity of human preferences, instead of trying to shoehorn those preferences into a narrow subset of categories.
We are tasked with creating standardized building blocks. The current approach seems to think of these “blocks” like Legos. The hope seems to be that we can find a particular combination of blocks that works as a language of sorts for expressing preferences.
But that’s going to be very limiting. Legos make for pretty poor communication mediums. And you’d need a LOT more blocks. Otherwise, you can only express a very small number of preferences with the two blocks we currently have (and even that’s assuming those blocks have a clear meaning which, as I argue above, one of them most certainly does not).
Instead I think a better building block analogue would be something like the building blocks of the maritime industry. Shipping containers are building blocks that have standardized and facilitated maritime commerce in so many ways. But they work because shipping containers are open-ended – they are capable of holding a wide variety of things.
We are also dealing with cargo that is varied — the diverse expressions of preferences of the millions of humans who create the web. And that cargo is being used for a wide variety of use cases and applications, many of which have yet to even be created.
Therefore, we should prefer the flexibility and durability of open-ended building blocks.
We are an unelected body and should be humble in our approach. We should not try to define which specific preferences ought to be allowed to be expressed, and which preferences should be silenced forever more.
We should instead seek only to offer a structured vessel for expressing those preferences – and thus to empower the millions of amazing humans who created the web to keep creating in this AI future that is being thrust upon us all.
I currently believe the most promising and most durable solutions will be found in purpose-based approaches, combined with preference selection structures that are open-ended.
I am open to any alternatives though, so long as they are human-first.
I very much want to achieve consensus and find a productive path forward. The status quo is awful and unsustainable for the open web.
Please contact me if you would like to discuss privately, either remotely or in Toronto. And that invitation extends especially to those of you who have differing opinions.
Cheers,
Nate